The Federal Data Catalog
The Federal Data Catalog (FDC) is the United States Federal Government’s primary data portal for the public through Data.gov. Data.gov provides the FDC, as well as additional resources that support federal agencies and the public regarding data governance of federal public data assets (principles and practices involved in the management and sharing of data). The site was launched by the General Services Administration (GSA) on May 21, 2009 at the direction of Vivek Kundra, the first Federal Chief Information Officer (Kundra, 2009) in response to the January 2009 Presidential Memorandum on Transparency and Open Government. The memorandum directed federal agencies to harness technology to promote transparency, participation, and accountability in government (Obama, 2009). The Office of Management and Budget’s (OMB) M-10-06 “Open Government Directive” that followed later that year went further, requiring that all federal agencies post at least three high-value datasets online and register them on Data.gov within 45 days (Office of Management and Budget, 2009). By the end of 2010, most federal agencies had published data on the platform, and by 2012 Data.gov’s holdings were regularly drawn upon by civil society organizations, researchers, and private businesses (U.S. General Services Administration, 2024). In 2013, the Obama Administration subsequently expanded its open government data policies with the back-to-back release of Executive Order 13642, which declared open and machine-readable data “the new default for government information,” and the Office of Management and Budget (OMB) implementation guidance known as M-13-13, “Open Data Policy - Managing Information as an Asset.”
M-13-13 required federal agencies to create enterprise data inventories (the precursor to what would later be called comprehensive data inventories (CDIs)), publish public data listings from those inventories at agency.gov/data.json, and have GSA populate those assets in Data.gov. The Foundations for Evidence-Based Policymaking Act of 2018 (The Evidence Act) signed into law on January 14, 2019 by President Trump codified much of the policy guidance articulated in M-13-13 (United States Congress, 2019) in its Title II, the Open, Public, Electronic, and Necessary Government Data Act (OPEN Government Data Act or OGDA). Under this law, federal agencies are required to maintain data assets as open data using standardized, machine-readable, non-proprietary formats, and the associated metadata for all of their data assets must be included in the FDC (Congressional Research Service, 2022). The Evidence Act required each agency to create and maintain a CDI that accounts for all data assets the agency “creates, collects, controls, or maintains.” It also required the OMB to promulgate additional implementation guidance within a year of enactment of the law.
That implementation guidance was slow to materialize. Six years and a day after the law’s enactment, as one of the final policy actions of the Biden Administration, OMB finally released M-25-05 “Phase 2 Implementation of the Foundations for Evidence-Based Policymaking Act of 2018: Open Government Data Access and Management Guidance” (Office of Management and Budget, 2025; Alder, 2025). The guidance requires all federal agencies and GSA to adopt an updated metadata schema for their CDIs and the FDC (known as DCAT-US 3.0), sets minimum metadata requirements required by the Evidence Act, provides guidance on how to prioritize data asset classification and review for public release as open government data assets, and clarifies what constitutes a data asset, public data asset, and open government data asset under the statute (Office of Management and Budget, 2025). Critically, M-25-05 rescinds and replaces M-13-13 while carrying forward its open-by-default philosophy and giving Chief Data Officers (a role that was statutorily created by the Evidence Act) specific responsibilities they did not have in 2013. Nearly all of the requirements in M-13-13 were preserved in M-25-05, including how agencies should publish CDIs in a common location. Among responsibilities articulated to the CDOs is ensuring that their agencies publish an open data plan and that the CDIs are updated and complete.
These CDIs form the harvest sources that populate the FDC, meaning that the quality, completeness, and timeliness of Data.gov is directly dependent on each agency’s diligence in maintaining its own inventory. The lengthy gap between the law’s passage and the issuance of implementation guidance had practical consequences: agencies proceeded with inconsistent metadata practices and varying interpretations of what belonged in a CDI, contributing to many of the challenges in using the FDC as a barometer for federal data integrity described below.
Challenges with using the Federal Data Catalog in monitoring open government data
The technical architecture of Data.gov has evolved considerably since its inception. The original portal relied on a custom-built catalog system, but in 2014 it was relaunched on CKAN (Comprehensive Knowledge Archive Network, which turned 20 years old this year (Popova, 2026)), an open-source data management platform developed by the Open Knowledge Foundation (U.S. General Services Administration, 2014). The CKAN-based catalog introduced a robust public API, federated search across geospatial and non-geospatial datasets, and a harvesting infrastructure that allows individual agencies to maintain their own metadata sources while GSA automatically aggregates them into a central catalog on a scheduled basis (U.S. General Services Administration, 2024). Rather than requiring agencies to manually submit records to a single curator, the harvesting model means that any additions, modifications, or deletions made to an agency’s metadata inventory are reflected in Data.gov at the next scheduled harvest - a design that has significant implications for interpreting fluctuations in the platform’s reported dataset count.
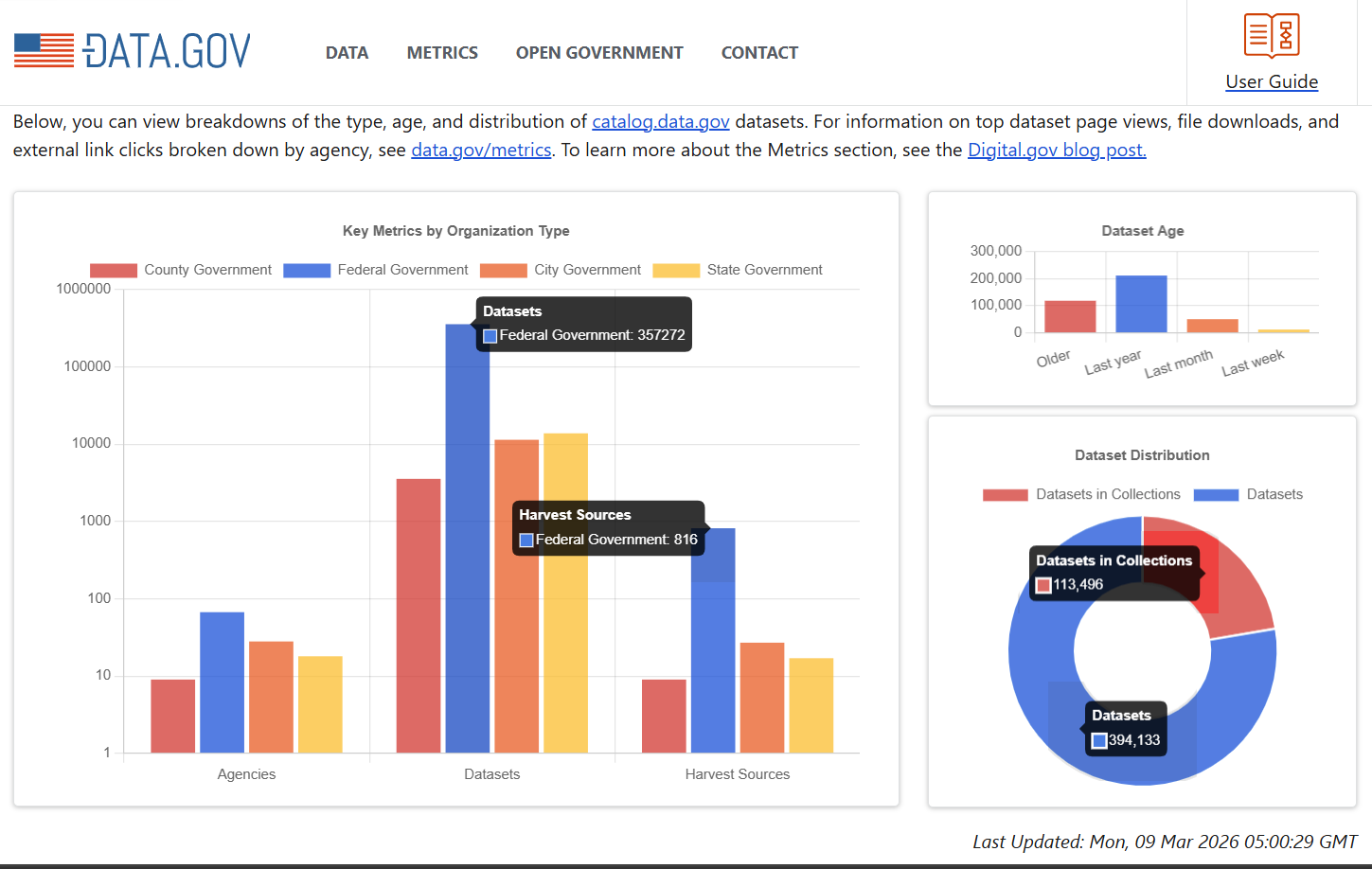 Figure: A composite of screenshots of the statistics on the Data.gov landing page from 03/09/2026. The statistics can be recovered using the CKAN API for live values or through snapshots captured by the WBM.
Figure: A composite of screenshots of the statistics on the Data.gov landing page from 03/09/2026. The statistics can be recovered using the CKAN API for live values or through snapshots captured by the WBM.
Inaccurate Assumptions
A clear understanding of what the FDC is and is not is a necessary precondition for using it to monitor open government data. Two common misunderstandings are particularly consequential.
The first is the assumption that the FDC is a data repository. It is not. As the platform’s own documentation states, the Data.gov catalog contains only metadata about datasets — including URLs, descriptions, and other descriptive information — but not the actual data assets themselves (U.S. General Services Administration, 2024). The underlying data continue to reside on agency servers, portals, and websites, with Data.gov providing only a pointer to where they can be found. The confusion about the FDC being a data repository may have resulted from language in the Evidence Act itself:
“The Administrator and the Director shall ensure that agencies can submit public data assets, or links to public data assets, for publication and public availability on the interface.” (P.L. 115-435)
Because of the history with how Data.gov was initially rolled-out as an index of metadata information about datasets only, then reinforced by OMB in M-13-13, the infrastructure of the FDC never supported acquisition of actual datasets. That the Evidence Act allows for either data or links to the data provides a pathway for the FDC to add this functionality at a later date (or to replace it with a successor catalog in the future, a possibility that is also articulated in M-25-05). This distinction matters enormously when the FDC is used as a proxy for monitoring data availability: a dataset can be listed in the FDC while the underlying data are inaccessible, modified, or even deleted from the agency’s own systems, and conversely, a dataset can be taken down from an agency website without any corresponding change in the FDC’s count if the agency’s CDI metadata record remains intact.
The second, and arguably more consequential, misunderstanding concerns the dynamic nature of the FDC’s dataset count. Because Data.gov is continuously and automatically harvesting metadata from agency sources on varying schedule the topline number of datasets displayed on Data.gov’s landing page fluctuates routinely as part of normal operations (U.S. General Services Administration, 2024). The number reflects the state of agency CDIs at the time of the most recent harvest, and it changes whenever agencies add, update, or remove entries from their own metadata inventories. These fluctuations are expected in the normal operations of the FDC. Some agencies sources are harvested daily, others weekly or monthly.
These two points were at the center of significant confusion during early 2025, when multiple press outlets and monitoring organizations cited changes in Data.gov’s total dataset count as a primary measure of data removals by the second Trump Administration (Koebler, 2025; Kutz, 2025; Mauran, 2025). Beginning in late January 2025, following a series of executive orders directing federal agencies to remove websites and data products deemed inconsistent with the new administration’s policy priorities, the total number of datasets listed on Data.gov’s homepage did decline noticeably from roughly 308,000 at the time of the inauguration to approximately 304,600 by late February 2025, a reduction of some 3,400 entries (Kutz, 2025). News coverage, social media, and advocacy organizations amplified these figures as evidence of a systematic data purge, leading members of Congress to respond with inquiries about why Data.gov was reporting such losses (Rep. Don Beyer, 2025). However, owing to the dynamic nature of the Data.gov harvesting routines, a forensic audit of the system done around that time in conjunction with this project reveals that the true change netted out to about zero. Ironically, all of the reported accounts were technically relying on the wrong count as the Data.gov topline does not include datasets that are part of collections (there are at least another 100,000 of those). The next iteration of the FDC will have a more accurate count once the site is fully released (see the beta-version here, which lists 515,111 datasets as of the date of this report).
Despite likely inaccuracies, attention to those figures was not entirely misplaced. Real and consequential removals of federal datasets from public access did occur in 2025. These have been documented in detail by health policy researchers (KFF, 2025), journalists (Robbins, 2025; Palmer, 2025), and advocacy organizations (National Security Archive, 2025). However, experts cautioned against treating the topline Data.gov count as a reliable or complete measure of those removals. At a public webinar convened by the Data Foundation in October 2025, panelists that included a former GSA Data.gov team lead and a former OMB senior statistician explained that the dataset count “is normally going to change all the time” due to routine harvesting activity, and that relying on it as a barometer of data integrity is fundamentally problematic for several compounding reasons (Data Foundation, 2025). The FDC may list a dataset as available while the link to that dataset points to an error page, and conversely, significant datasets that have never been properly indexed in agencies’ CDIs will not appear in (or perhaps even disappear from) the catalog at all, regardless of what happens to the actual data (Data Foundation, 2025). As one panelist summarized, the catalog represents information about data, not the data themselves, and the integrity of that information is only as strong as the metadata practices of the agencies that feed it.
Incomplete Catalog
There are currently over 500,000 data assets inventoried in the FDC (including datasets that are part of aggregated collections). While this is a non-trivial figure, it represents just a tiny fraction of all the data assets that federal agencies possess. Most data assets that federal agencies hold have not gone through the prioritization and review process required by M-25-05 and the Evidence Act. Even when data assets are publicly available through internet download they may be not be included an a CDI.
One example of publicly available data assets held by a federal agency but not indexed in the FDC comes from the Department of State’s President’s Emergency Plan for AIDS Relief (PEPFAR) dataset website, which was previously administered by USAID. The website currently lists seven datasets available for download in two programs. None of those datasets are listed in either the Department of State’s current or historical data inventories nor those formerly maintained by USAID or CDC (which also collected data through PEPFAR). The absence of these datasets in the FDC means that when 17 previously available datasets were removed by this Administration in 2025 from the website, those changes would not be reflected on Data.gov and its summary statistics.
Incomplete coverage of agency data holdings is not solely the result of agency negligence or deliberate omission. Under the harvesting model, Data.gov can only index what agencies have documented in their CDIs. For agencies whose CDO and CIO offices have been historically under-resourced — a condition that the Phase II guidance for the Evidence Act explicitly acknowledged as a systemic problem (Office of Management and Budget, 2025) — maintaining a complete and current inventory of all data assets is a substantial operational and resource burden. Moreover, the Evidence Act’s definition of a data asset is broad enough to encompass a vast range of information products, many of which agencies have never systematically catalogued. The statutory requirement to account for all data assets created, collected, or maintained by an agency subject to an assessment of whether the costs and benefits to the public of converting a data asset into a machine-readable format are favorable. In practice, Congress’s intent of openness-by-default describes an aspirational standard that no federal agency has yet achieved.
The incompleteness of the FDC was further exacerbated in 2025 by workforce reductions affecting the GSA team responsible for maintaining Data.gov itself. At the beginning of 2025, that team comprised five government employees along with contractor support; by October of the same year, only two government employees remained in the office, with reduced contractor support and a heavier workload as a result of the departures of their colleagues (Data Foundation, 2025). These staffing changes have had direct implications for GSA’s ability to fulfill its own statutory obligations under M-25-05, including maintaining a current and accurate FDC.
Inaccurate Metadata
Incomplete metadata information is a major issue with both individual agencies’ CDIs and, as a result, the FDC. The Evidence Act requires that all agencies publish a CDI and that those entries appear aggregated in the FDC (i.e., as provided by Data.gov).
The Evidence Act and the subsequent OMB guidance in M-25-05 lay out the minimal requirements for such metadata. Moreover, the updated DCAT-US 3.0 metadata schema, required by OMB per M-25-05 to be used by all federal agencies and GSA in promulgating the inventories and the FDC, standardizes the formatting of both optional and required metadata (Office of Management and Budget, 2025). However, significant gaps remain as agencies’ CDO and CIO offices have been historically under-resourced with respect to maintaining their CDIs. Among those most pertinent to understanding the integrity of open government data assets is the failure of agencies to include, or maintain, the exact URLs where individual datasets can be downloaded by the public. Under the DCAT-US schema, the distribution property in the JSON files should include the following information in its array:
"distribution": [
{
"@type": "dcat:Distribution",
"downloadURL": "",
"mediaType": "",
"title": ""
}
]
This is in addition to the optional inclusion of a landing page that describes a dataset or set of datasets in a separate field:
"landingPage": ""
In some cases, an agency will provide a landing page URL that provides additional links to download individual datasets. Again, the best practice — and requirement — is to include those individual URLs in the CDI itself under the distribution property in the JSON file. For example, the VA’s National Center for Veterans Analysis and Statistics has a landing page describing the Geographic Distribution of VA Expenditures (GDX) data. The landing page includes links to the annual Expenditures Tables, which are provided as Excel files through separate downloadable links (note that, technically, Excel xls files are proprietary and out of compliance with the Evidence Act as they are not in an open format). The VA’s CDI, however, only partially indexes each of these files.
Misclassifications of Data Assets
As discussed above regarding the aggregating of datasets into collections, the total number of entries in the FDC, which is used to populate the totals reported on the Data.gov landing page, is not an accurate estimate of the total number of data assets in the FDC. However, additional errors are introduced into this count simply because agencies often misclassify information as a data asset.
Many agencies include information products, such as reports, infographics, documentation, data tools, software, and other documents in their CDIs. These do not meet the statutory definition of a data asset under the Evidence Act (e.g., “a collection of data elements or data sets that may be grouped together”). An entire section of the OMB implementation guidance for M-25-05 (Section 4) was dedicated to helping agencies understand this definition of a data asset so they can more accurately update their CDIs (Office of Management and Budget, 2025).
For example, the CDC includes an infographic in their CDI ``Going Smokefree Matters - In Your Home Infographic.’’ This document is clearly not a dataset — however, the metadata entry in the CDI that is harvested by Data.gov wrongly indicates that it is a dataset in the @type field:
{
"@type": "dcat:Dataset",
"accessLevel": "public",
"bureauCode": [
"009:20"
],
"contactPoint": {
"@type": "vcard:Contact",
"fn": "OSHData Support",
"hasEmail": "mailto:nccdoshinquiries@cdc.gov"
},
"description": "Explore the Going Smokefree Matters – In Your Home Infographic which outlines key facts related to the effects of secondhand smoke exposure in the home.",
"distribution": [
{
"@type": "dcat:Distribution",
"downloadURL": "https://data.cdc.gov/download/k4xj-uge6/application/pdf",
"mediaType": "application/pdf"
}
],
...
}
Following the CDC’s data inventory API endpoint for this entry, reveals that the infographic is entered as a “file” in the assetType field:
{
"id" : "k4xj-uge6",
"name" : "Going Smokefree Matters - In Your Home Infographic",
"assetType" : "file",
"averageRating" : 0,
"blobFilename" : "Going Smokefree Matters - In Your Home Infographic.pdf",
"blobFileSize" : 552143,
"blobId" : "ac7da77d-4178-4ab1-951e-d7b58d03c01a",
"blobMimeType" : "application/pdf; charset=binary",
...
}
 Figure: An example of an infographic by the Centers for Disease Control and Prevention inaccurately accessioned as a data asset in the FDC. Available for download at: https://data.cdc.gov/download/k4xj-uge6/application/pdf
Figure: An example of an infographic by the Centers for Disease Control and Prevention inaccurately accessioned as a data asset in the FDC. Available for download at: https://data.cdc.gov/download/k4xj-uge6/application/pdf
Compare that with the CDC’s API endpoint of their “NNDSS - Table II. West Nile virus disease”, which is also listed as a dataset in Data.gov, albeit correctly:
{
"id" : "r7hc-32zu",
"name" : "NNDSS - Table II. West Nile virus disease"",
"assetType" : "dataset",
"attribution" : "Division of Health Informatics and Surveillance (DHIS), Centers for Disease Control and Prevention",
"averageRating" : 0,
"category" : "NNDSS",
...
}
Errors are present
The process of adding, modifying, or removing entries into the inventory can be error-prone. Even with strong data governance principles, such as using controlled vocabularies and standard operating procedures for naming conventions and metadata, mistakes happen. Whether these are the result of one-off human data entry mistakes, or systematically encoded into automation pipelines, the errors manifest across the FDC. Both the EPA and VA use-cases described above demonstrate examples of typos in the titles and descriptions of CDI entries. However, more consequential errors are also present in the FDC.
Take, for instance, the US International Trade Commission’s (USITC) highly regularized releases of the Harmonized Tariff Schedule of the United States (HTSUS). This high-profile dataset is used by federal agencies and industry to understand the tariff rates and statistical categories of all goods imported into the United States throughout a given calendar year. Typically, the USITC follows a naming convention for this dataset of [TITLE]([YEAR]), where TITLE is the name of the dataset and YEAR is the year of coverage. The URLs generated by GSA when creating landing pages in the FDC use the same information. In 2025, however, an error was introduced somewhere in the processing pipeline and the URL for the 2025 release has an FDC landing page URL on Data.gov that implies it is the 2024 release:
https://catalog.data.gov/dataset/harmonized-tariff-schedule-of-the-united-states-2024
This URL was previously the landing page of the actual 2024 release, evident from an early 2024 WBM snapshot:
https://web.archive.org/web/20240528054332/https://catalog.data.gov/dataset/harmonized-tariff-schedule-of-the-united-states-2024
Thankfully, the Data.gov harvester and landing page generation routines have reasonable fail-safes. As a dynamic site however, rather than preventing the overwriting of an existing URL, the system generates landing page URLs as it encounters them in its FDC source, which is sorted from most recent to least by default. As a result, the true 2024 release has a new active landing page URL with a random suffix appended to the end:
https://catalog.data.gov/dataset/harmonized-tariff-schedule-of-the-united-states-2024-41c71
This type of error is consequential because it limits the ability of users to construct reliably persistent URLs from source information. It also breaks the intended endpoint of links within existing content, directing users to potentially wrong sources. With this specific case, the error appears to have induced a data duplication issue with at least one data preservation initiative. For instance, there are two entries in Harvard’s Data.gov archive search results for the 2024 HTSUS, both appearing to archive the same 2024 data.
Perhaps the most egregious error from a data integrity perspective present in the FDC is the pervasive problem of invalid URLs that purport to link to data assets. These errors can arise from typos and other input errors (i.e., filename encoding issues) in the harvest sources. However, one more insidious cause is link rot — that is, the deprecation of a valid URL to an invalid URL over time as files are moved, websites are restructured, et cetera. As an example of link rot, consider the Office of Management and Budget’s Public Budget Database - Governmental receipts 1962-Current entry in the FDC. When the metadata for this entry was last updated on 3/22/2024, the download URL pointed to: https://www.whitehouse.gov/wp-content/uploads/2024/03/receipts_fy2025.xlsx. Because the White House website was taken down and slowly rebuilt after the new Trump Administration took office—and because the Administration moved to excise spending data from public view—this URL was lost to link rot. Rather than suffer this avoidable fate, the URL should have been updated in the OMB metadata to point to the National Archives’ copy of the Biden White House website during the transition: https://bidenwhitehouse.archives.gov/wp-content/uploads/2024/03/receipts_fy2025.xlsx.
Conclusion
Data.gov and the FDC are critical national data infrastructure, providing the public with a significant resource to discover data supported by taxpayers. However, misunderstandings about how that resource can be appropriately used and the nature of its limitations can lead to confusion over how it should be considered in the context of federal data integrity issues experienced in 2025 (and into early 2026). Importantly, the topline count of federal data assets reported on Data.gov is a signal only of what is indexed at a moment in time and subject to both mundane and irregular changes to its harvest sources.
This mismatch between the FDC’s signals and underlying data reality runs in both directions. Some of the most significant documented data removals of 2025 involved datasets and websites that were never indexed in the FDC in the first place. These included PEPFAR datasets, OMB apportionments data, and many data tools. Their removal was invisible to any analysis based on Data.gov’s dataset count. At the same time, many entries in the FDC contained broken or stale URLs pointing to resources that had been reorganized, taken offline, or deleted long before 2025, a phenomenon known as link rot. The net effect is that the FDC’s total dataset count is an unreliable single-number proxy for the actual availability of federal data, capable of both overcounting (by including misclassified assets, stale records, and entries without working URLs) and undercounting (by missing datasets that are publicly available but never properly inventoried).
References
- Alder, M. (2025). White House finalizes OPEN Government Data Act guidance, restarts CDO Council. FedScoop. https://fedscoop.com/white-house-open-government-data-act-restarts-cdo-council/
- Koebler, J. (2025). Archivists Work to Identify and Save the Thousands of Datasets Disappearing from Data.gov. 404 Media.
- Kundra, V. (2009). Data.gov Launch Announcement. U.S. General Services Administration, Technology Transformation Services. https://data.gov/timeline/
- Kutz, A. (2025). How much federal data has Trump really purged? NewsNation. https://www.newsnationnow.com/politics/trump-federal-datasets-websites/
- Mauran, C. (2025). Thousands of datasets from Data.gov have disappeared since Trump’s inauguration. What’s going on? Mashable. https://mashable.com/article/government-datasets-disappear-since-trump-inauguration
- Obama, B. (2009). Memorandum on Transparency and Open Government. Presidential Memorandum. https://obamawhitehouse.archives.gov/the-press-office/transparency-and-open-government
- Palmer, K. (2025). Preserving the Federal Data Trump Is Trying to Purge. Inside Higher Ed. https://www.insidehighered.com/news/government/science-research-policy/2025/06/10/preserving-federal-data-trump-trying-purge
- Popova, Y. (2026). CKAN Turns 20: Two Decades of Open Data Infrastructure. CKAN Blog. https://ckan.org/blog/ckan-turns-20-two-decades-of-open-data-infrastructure
- Robbins, R. (2025). STAT is backing up and monitoring CDC data in real time: See what’s changing. STAT News. https://www.statnews.com/2025/02/14/tracking-cdc-data-changes-trump-executive-order-targets-gender/
- Congressional Research Service. (2022). The OPEN Government Data Act: A Primer (No. IF12299; Issue IF12299). Congressional Research Service. https://www.congress.gov/crs-product/IF12299
- Data Foundation. (2025). Taking Stock of Federal Open Data in 2025. Data Foundation Blog. https://datafoundation.org/news/blogs/707/707-Taking-Stock-of-Federal-Open-Data-in-
- KFF. (2025). A Look at Federal Health Data Taken Offline. KFF Policy Watch. https://www.kff.org/policy-watch/a-look-at-federal-health-data-taken-offline/
- National Security Archive. (2025). Disappearing Data: Trump Administration Removing Climate Information from Government Websites. National Security Archive, George Washington University. https://nsarchive.gwu.edu/briefing-book/climate-change-transparency-project-foia/2025-02-06/disappearing-data-trump
- Office of Management and Budget. (2025). Phase 2 Implementation of the Foundations for Evidence-Based Policymaking Act of 2018: Open Government Data Access and Management Guidance. https://www.whitehouse.gov/wp-content/uploads/2025/01/M-25-05-Phase-2-Implementation-of-the-Foundations-for-Evidence-Based-Policymaking-Act-of-2018-Open-Government-Data-Access-and-Management-Guidance.pdf
- Office of Management and Budget. (2009). OMB Memorandum M-10-06 - Open Government Directive. https://obamawhitehouse.archives.gov/open/documents/open-government-directive
- Rep. Don Beyer. (2025). 79 U.S. Representatives Demand the Restoration of Public Access to Federal Data Sets Purged by the Trump Administration. Official Website of U.S. Representative Don Beyer. https://beyer.house.gov/news/documentsingle.aspx?DocumentID=6384
- U.S. General Services Administration. (2024). Data.gov Program Timeline. Data.gov. https://data.gov/timeline/
- U.S. General Services Administration. (2014). Data.gov CKAN Catalog Launch. Data.gov Blog. https://data.gov/announcements/datagov-ckan-catalog/
- U.S. General Services Administration. (2024). Data.gov User Guide. Data.gov. https://data.gov/user-guide/
- United States Congress. (2019). Foundations for Evidence-Based Policymaking Act of 2018 (No. P.L. 115-435; Issue P.L. 115-435). United States Congress.